用ChatGPT做一个AI法律助手
前言
ChatGPT 作为一个语言模型,其回答的内容受限于其之前训练过的数据集,它的回答可能会受到诸如数据源,语言表达方式,领域背景等复杂条件和限制的影响。因此如果直接询问ChatGPT法律规定问题,它能给你胡诌出花来。恰好Github大佬 @lvwzhen 发布了一个开源项目 law-cn-ai - AI法律助手,通过整合法律数据[1]来提高 ChatGPT 的响应准确性,从而更好的提供准确的法律建议。
对于普通人来说,使用这样的AI法律助手可以更方便地了解法律常识,更准确地判断司法实践,并获得更准确的建议和指导。
项目地址
lvwzhen/law-cn-ai: ⚖️ AI 法律助手 (github.com)
部署事项
作者提供了Vercel一键部署,Supabase 集成将自动设置所需的环境变量并配置对应的数据库概要,只需要点击下面的按钮:

就会跳转到Vercel一键部署页面,点击项目名称右下角的 Create按钮,添加 Supabase。
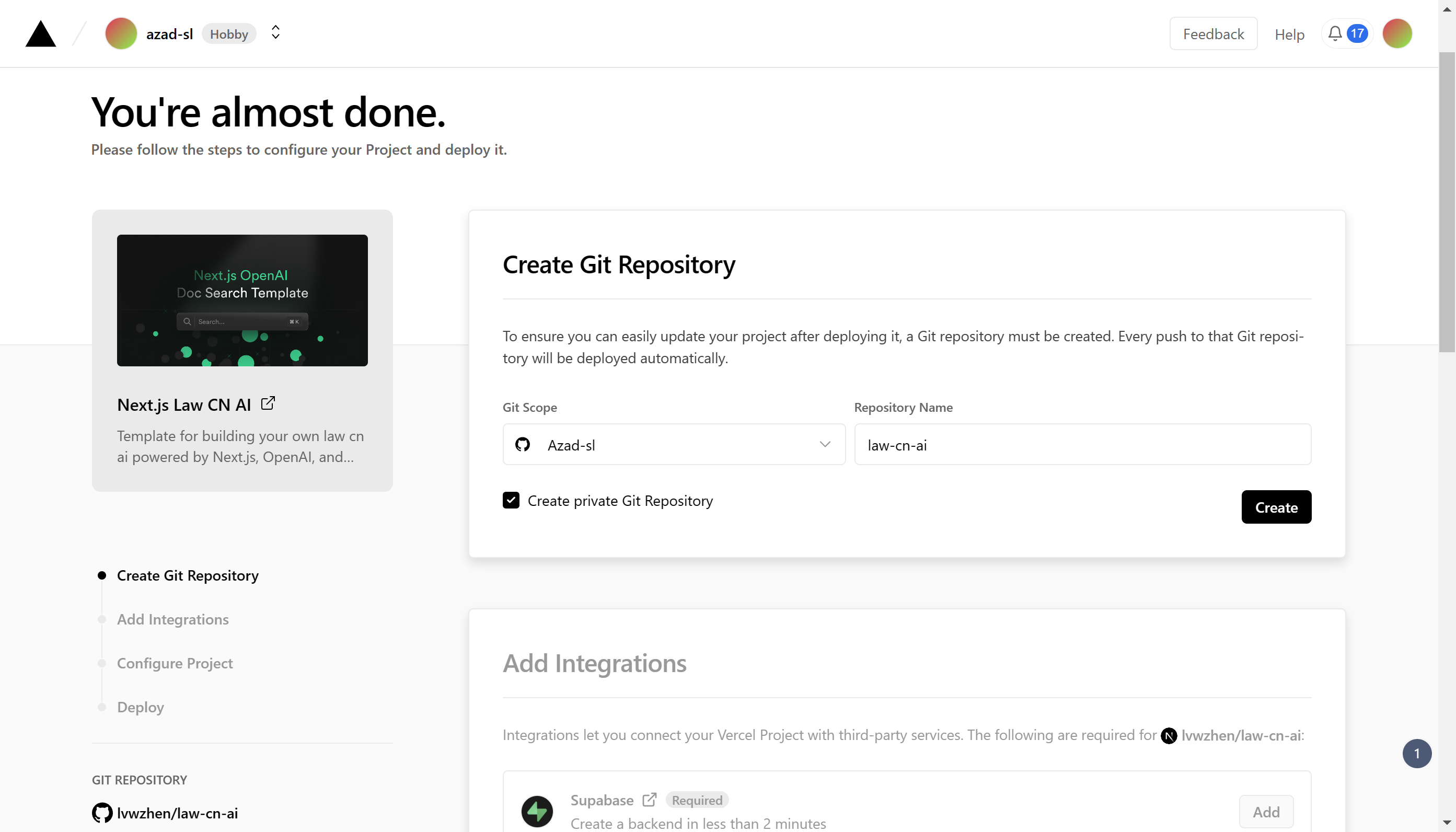
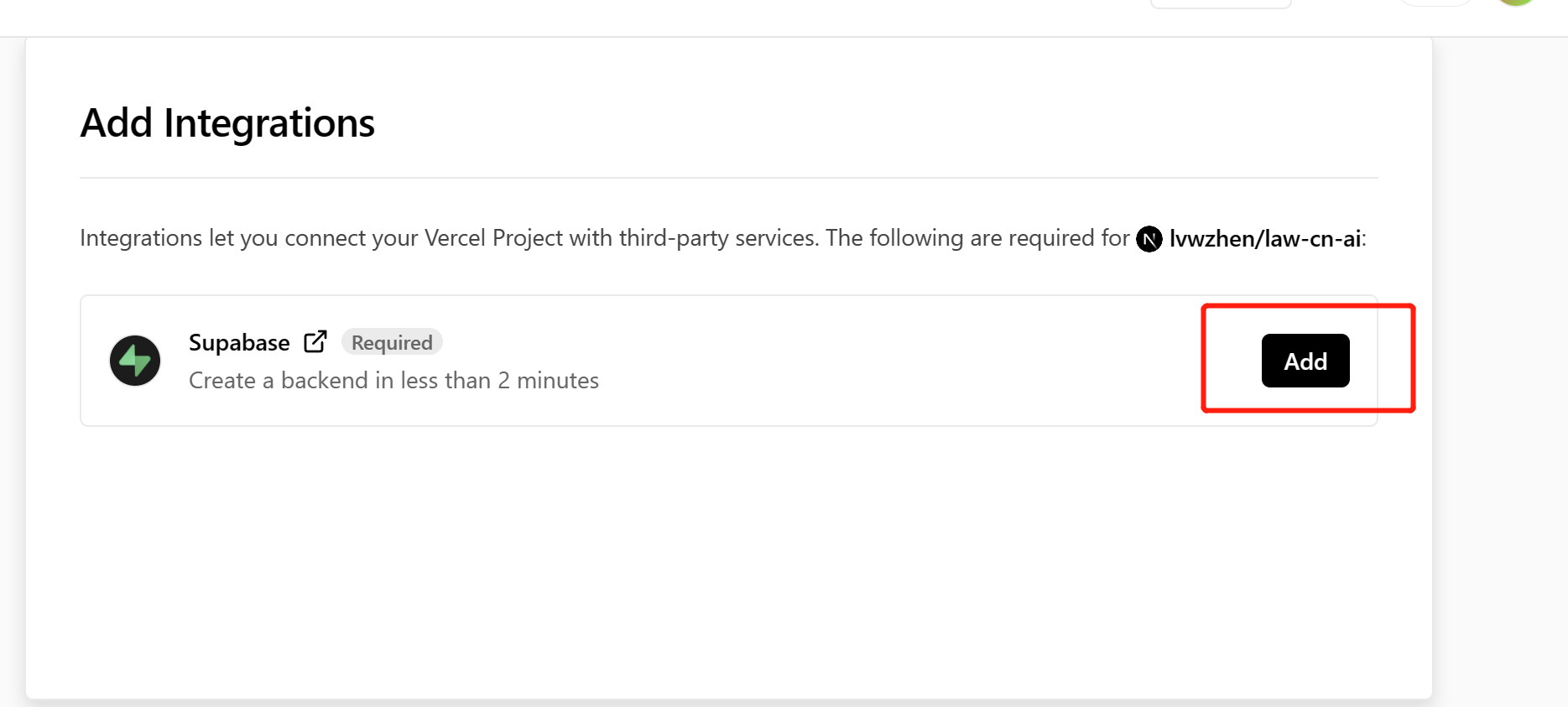
在弹出来的窗口,选择Github账户授权登录,Supabase可能会让你创建一个新的组织,简单创建一个,显示创建失败不要紧,多点几次。之后选择对应的Vercel project,点击下方的 Deploy。
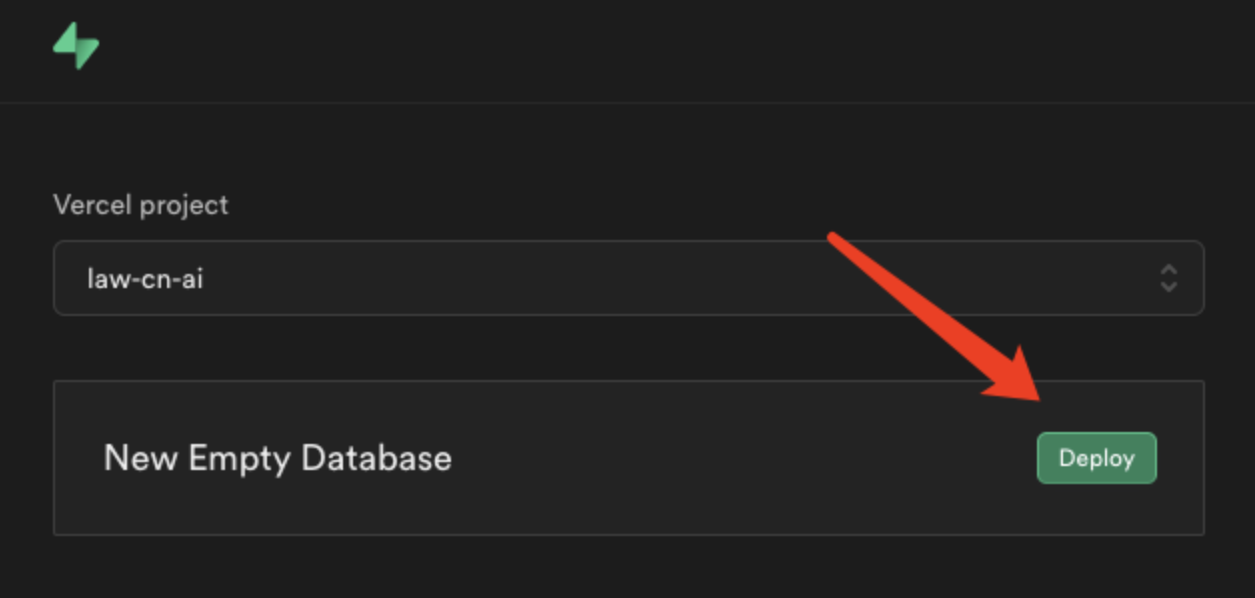
创建一个新的Project。地区选择亚洲地区。
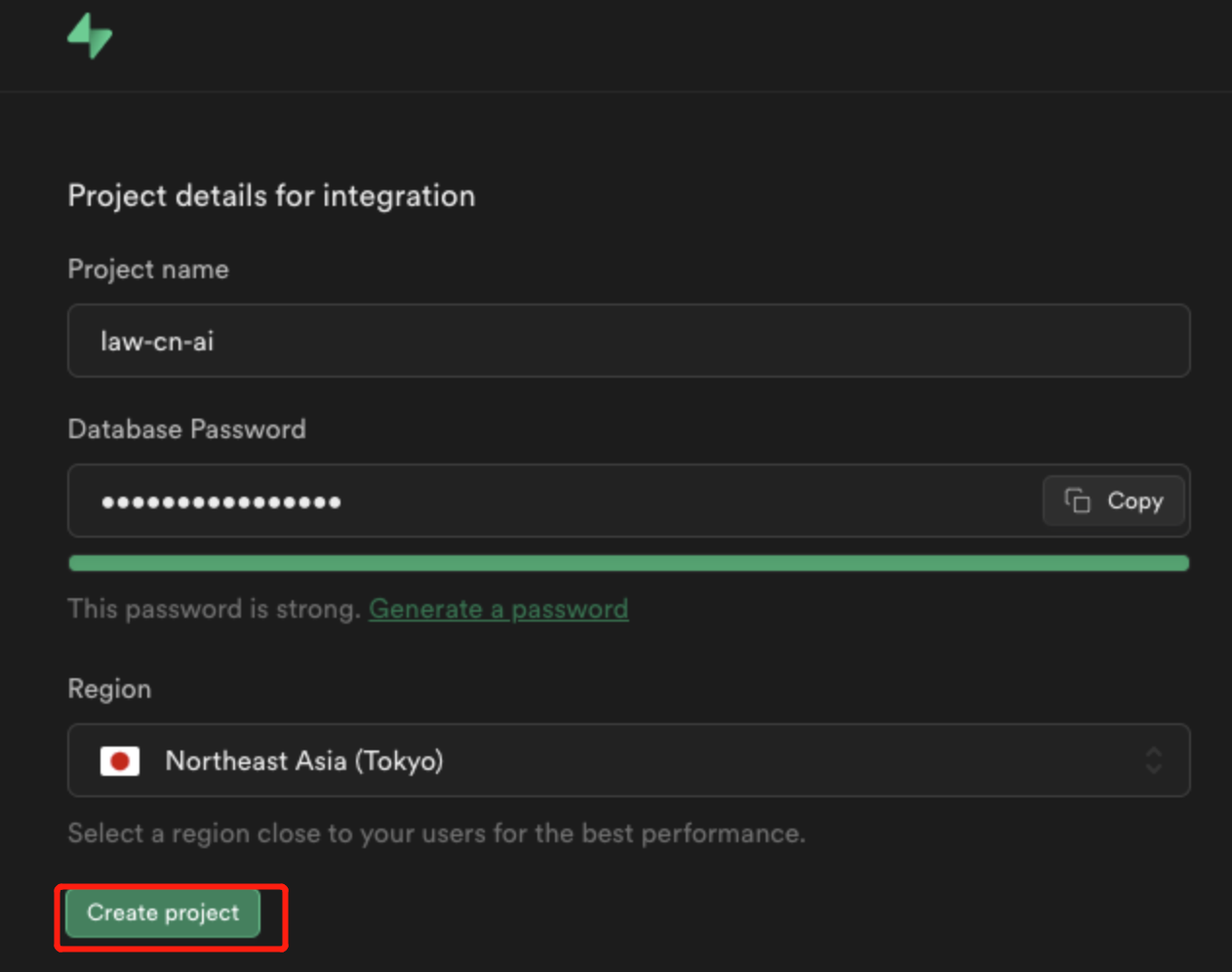
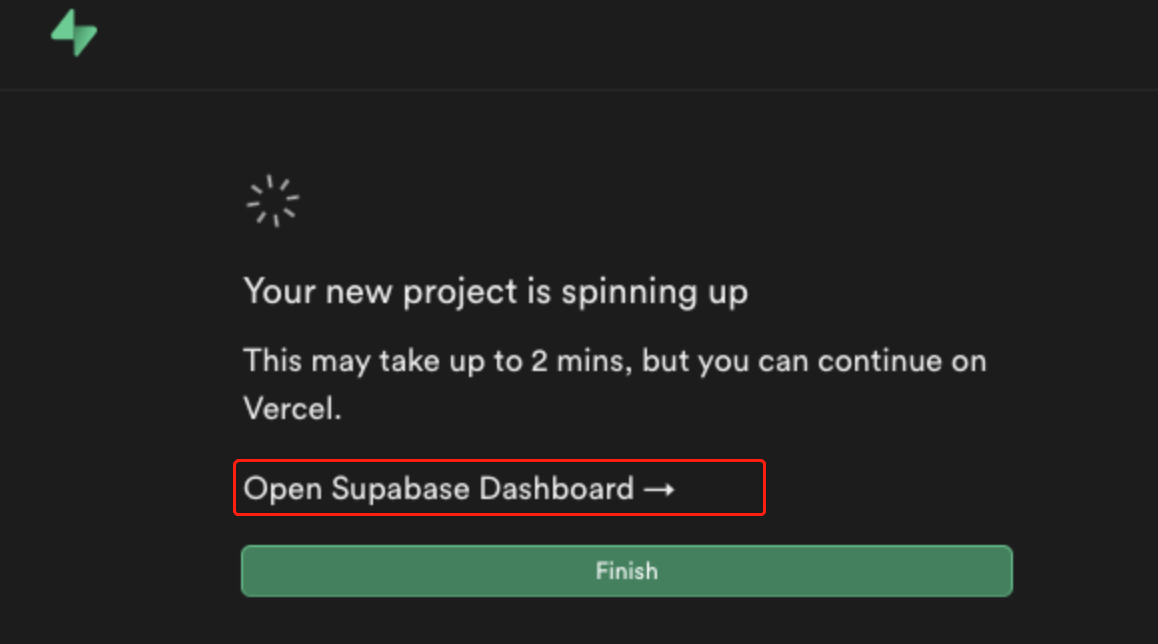
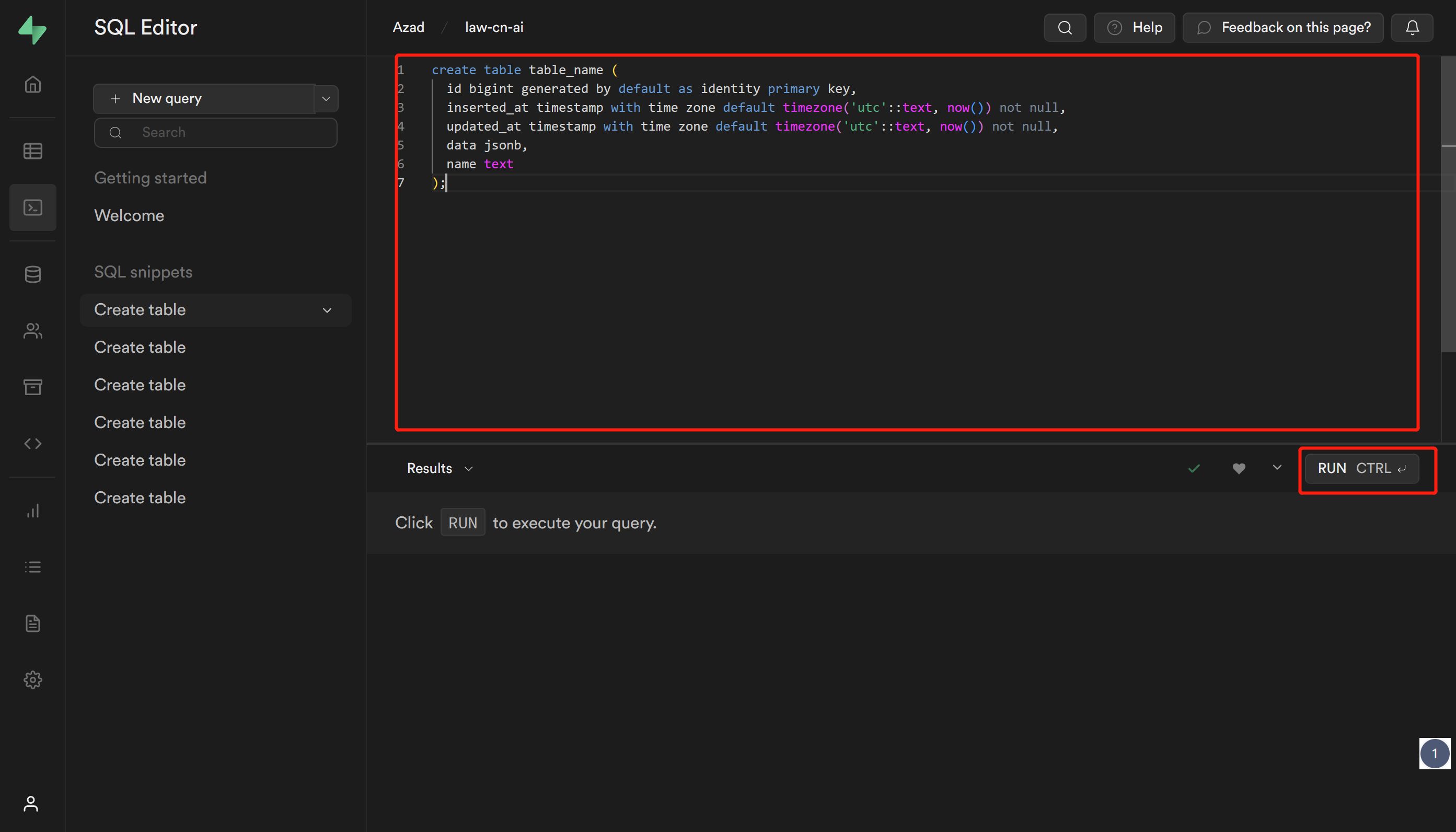
这里无需等待结束,直接点击 Open Supabase Dashboard,进入项目之中,配置数据库,按照图示创建表格:
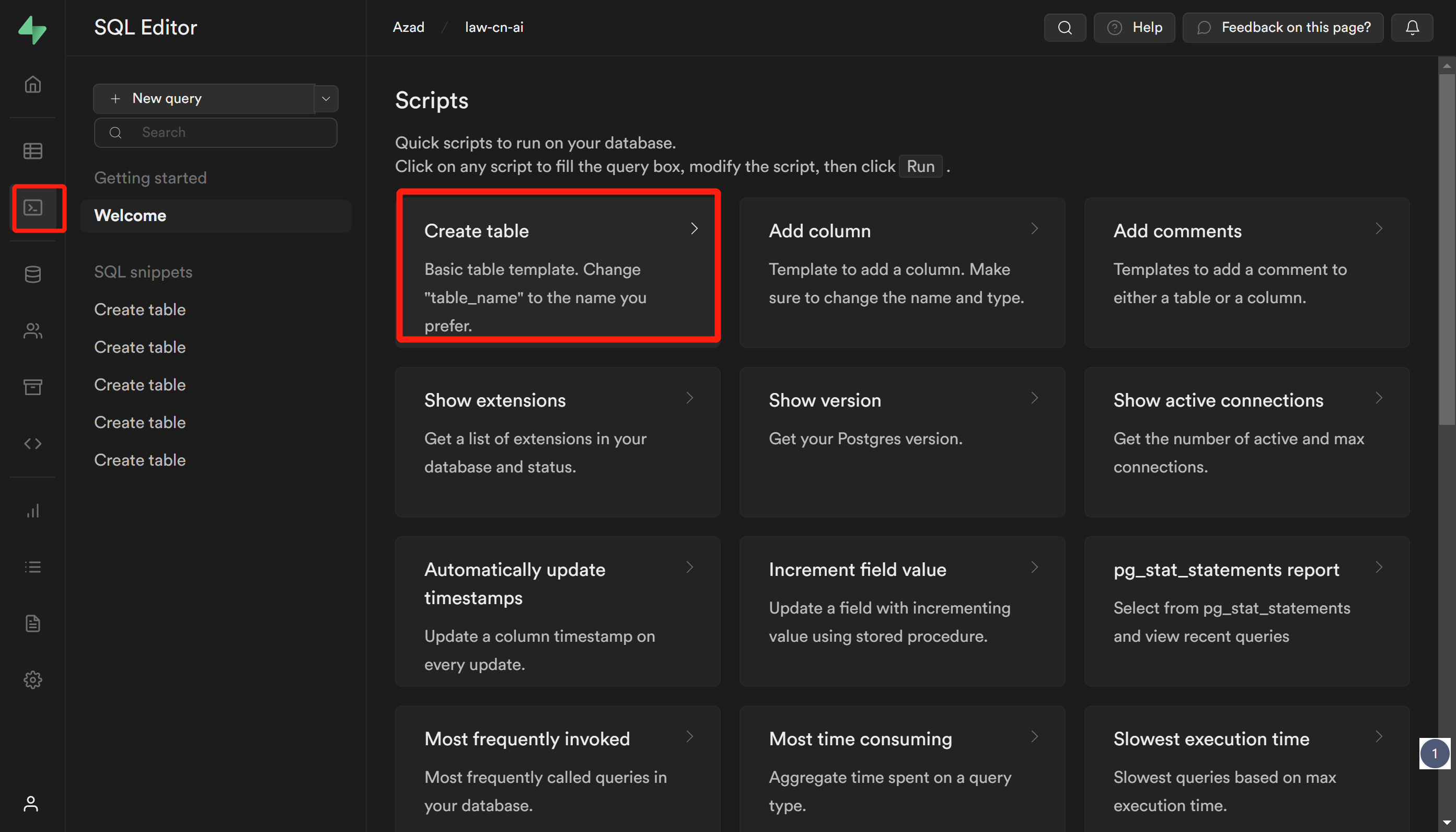
回到仓库,复制sql。文件路径在supabase/migrations/20230406025118_init.sql :
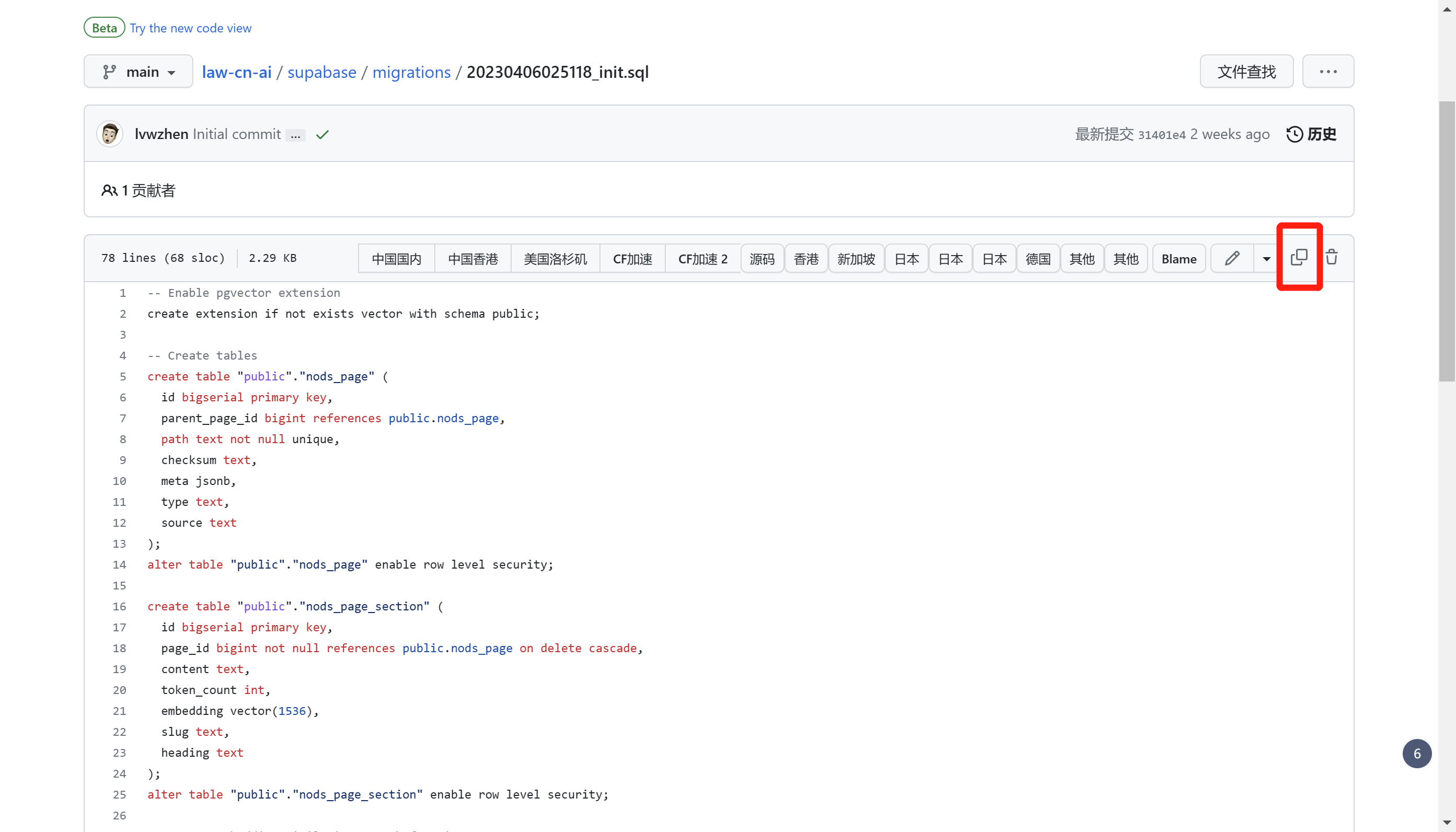
将复制的sql数据黏贴到这里,点击 RUN,之后等待运行成功:
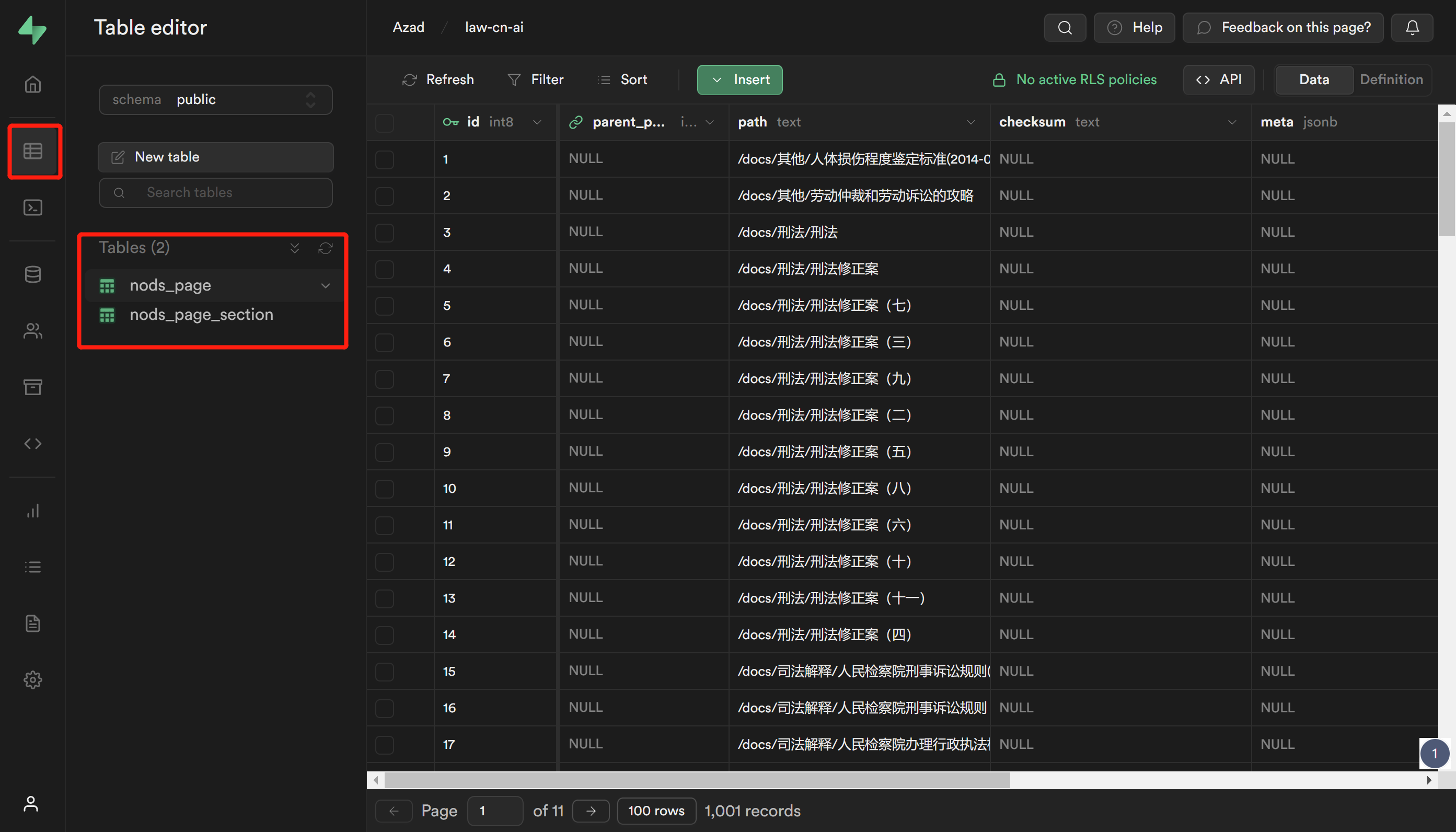
运行成功之后,会在数据库里创建两个数据表(法律文件来源:https://github.com/LawRefBook/Laws):
再回到Vercel,Supabase 已经添加成功:
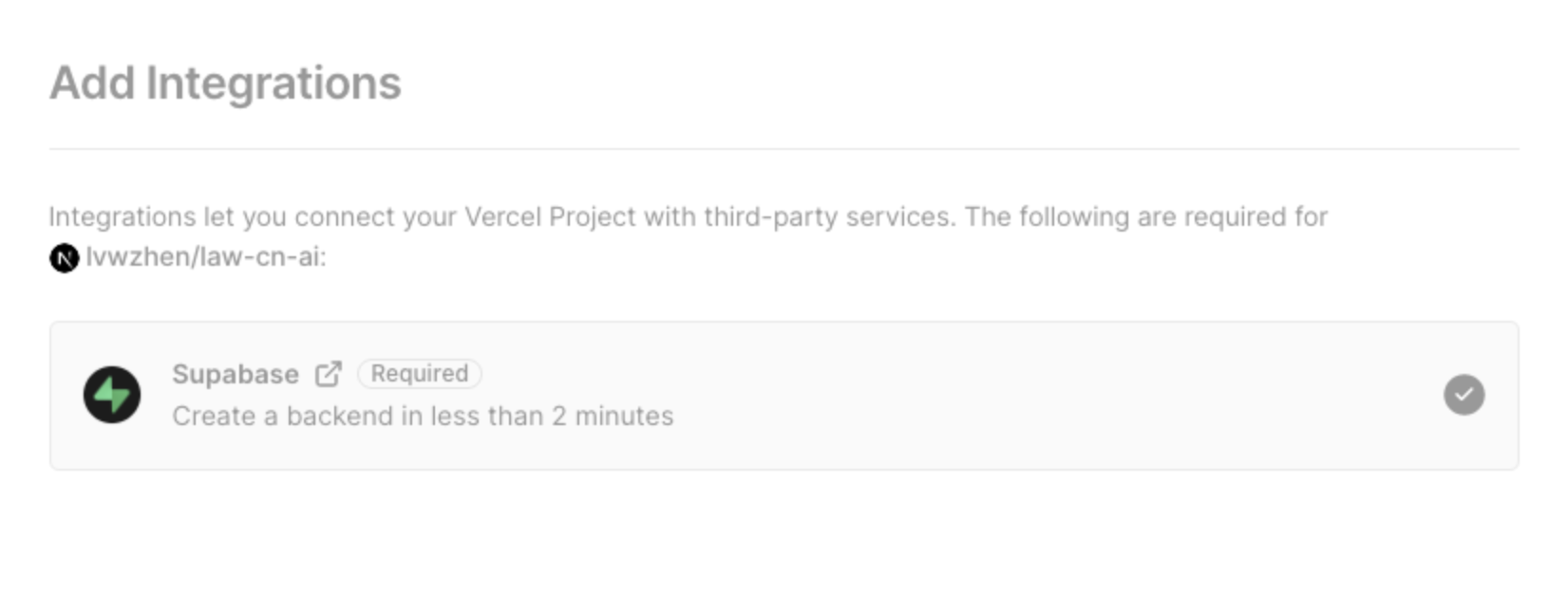
接着设置OPENAI_KEY,点击 Deploy 开始部署。
几点注意
-
构建部署时间会比较久,因为涉及数据库的全部法律法规计算,Vercel免费构建有最长45分钟限制,因此我又手动部署了三次(重新部署会跳过此前已经
reploy过的数据,不用担心重复),大概用时160分钟,约消耗了3刀API额度。
-
在部署过程中,可能会遇到一些资料计算 embedding 失败的情况,导致出现
one/multiple of its page sections failed to store properly。部署成功的话仍然可以正常使用,但是这些失败的内容将无法被检索。实测多次重新部署进行重试可以解决这个问题。 -
部署成功后运行可能会出现
服务器繁忙,请稍后再试! 或者自行部署,有两种可能:- 一种参照第2点,重新部署进行重试;
- 一种可能是API的问题,在这里 - 查询OpenAI-API密钥信息查询一下API是否失效,若失效了在项目的
Setting-Environment Variables修改重新部署。
结语
放上部署成功截图🎉
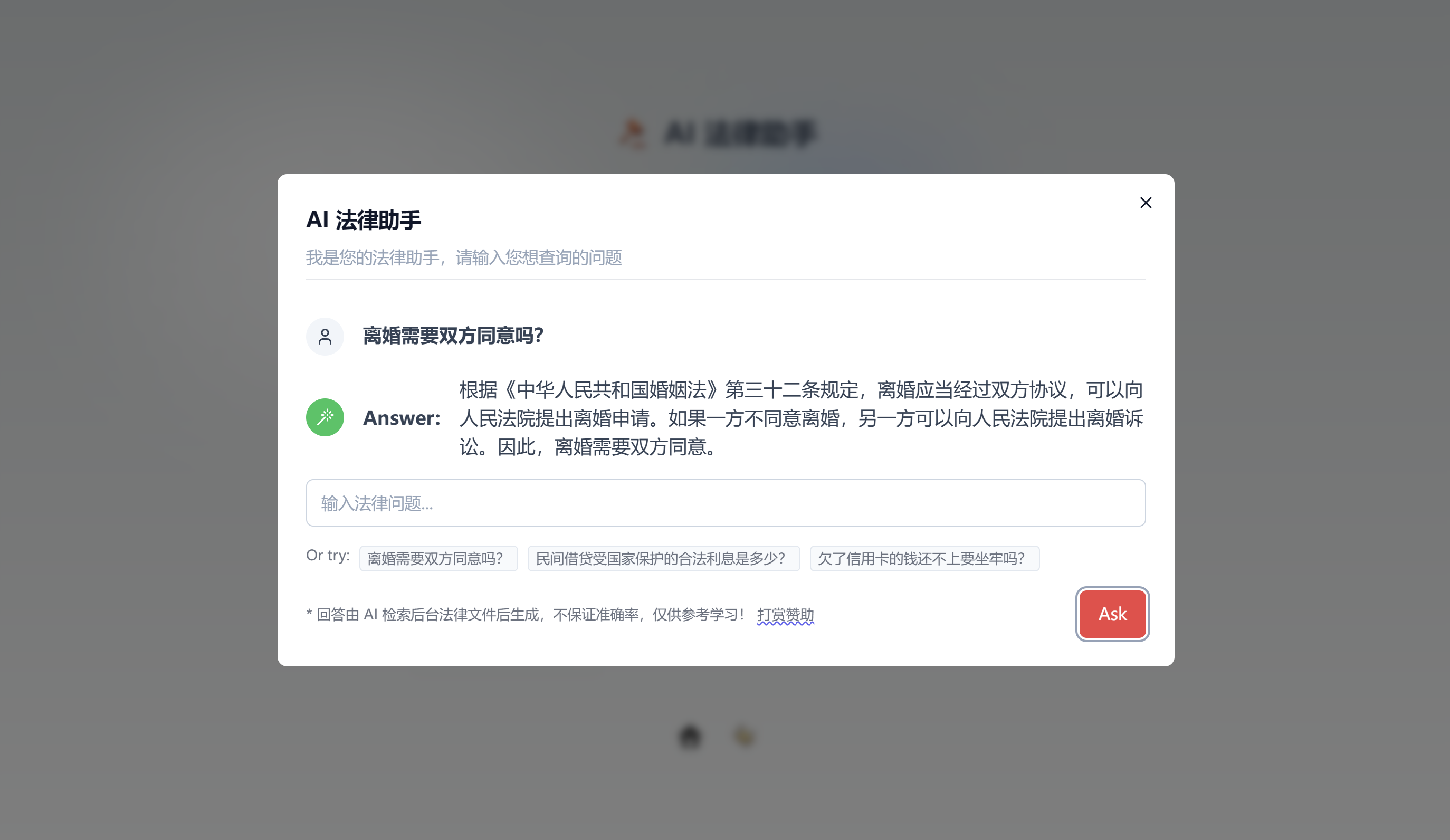
没有设置上下文,一问一答,几次测试的回答还是比较靠谱的,后台文件都能找到列举的法规,提问法律范畴之外的问题,会直接回答:“I'm sorry, I cannot assist with this.”🤣 用于平时的法规咨询等参考学习应该问题不大,如果有较深入的法律咨询需要,建议还是寻找相关的专业人士。

